Kasten is the Cure for Container Chaos
Kasten is a solution to a problem that shouldn't exist, but does because people are terrible.
Kasten (now owned by Veeam) is backup for data stored in containers. You know, those stateless encapsulations of programs that you can spin up and down all over the place? The ones that are highly mobile because they have no state in them? The ones that avoid data migration challenges by not having data?
Yeah, so, it turns out that people hate stateless containers and really want to put state in them which means lots of important data was ending up in containers with no data protection. After losing a bunch of important data that wasn't being protected, a lot of people have decided that maybe data protection for state being kept in containers would be a good idea. And thus: Kasten.
Kasten aims to address the yawning chasm of data protection functionality in Kubernetes. Here, for example, is a diagram presented by Kasten at CFD13 of the current state of Kubernetes data protection as viewed by the Kubernetes community. Kasten acknowledged that it doesn't even cover things like changed-block tracking or continuous data protection.
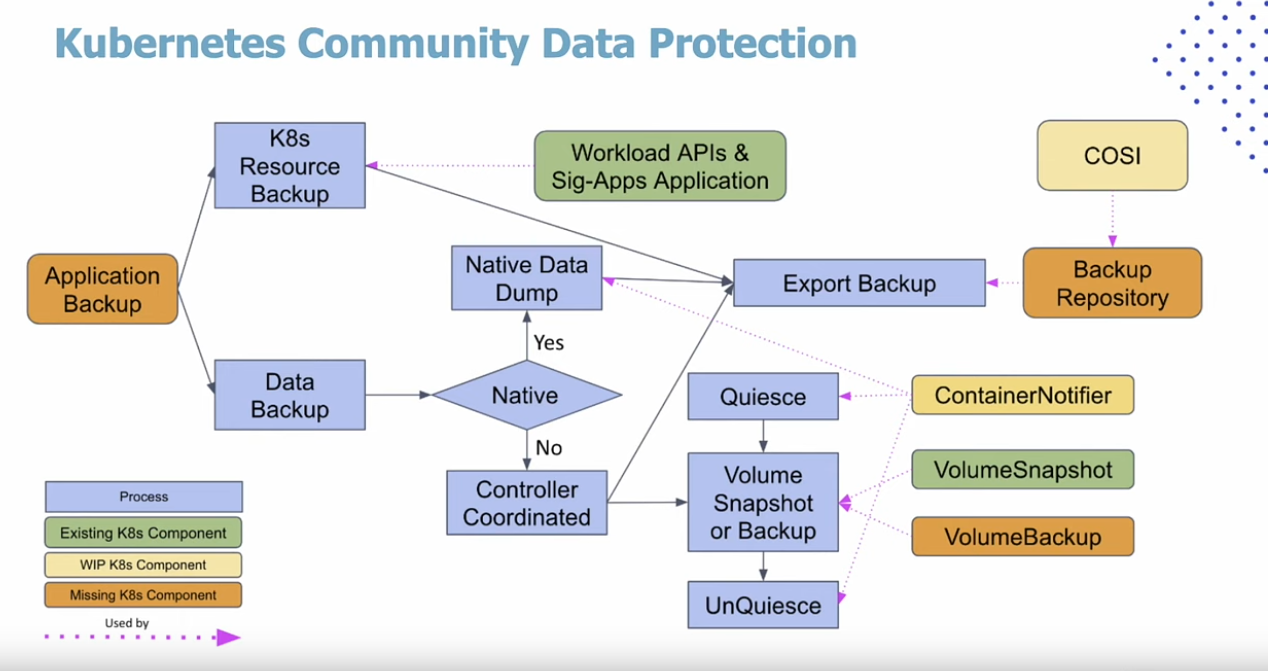
Because I have a dark and ironic sense of humour, I find this pretty funny.
I lived through the transition from bare metal to VMware-hosting and I remember the pain of backing up data that lived inside virtual machines with tools designed for bare-metal servers. Restoring a single file that lived inside a VM was a frustrating and painful exercise, let alone more esoteric concepts like incremental backups or consistency groups. We are, once again, having to re-implement all the same ideas that were already pretty much solved at a previous level of abstraction, but only after people have gone and put important data on systems that enjoy losing that data at random intervals.
Hail Eris!
The change in abstraction layer does mean that a bunch of other things need to change. Containers, and Kubernetes, operates differently to virtual machines or bare metal. While there are lots of similarities (as we saw above) Kubernetes has its own concepts, idioms, and ways of doing things are are markedly different to how other infrastructure works. Containers are more ephemeral and prolific than virtual machines. Co-tenancy is more prevalent. The way the APIs work is different, and there are generally a lot more moving parts.
Kubernetes is also additive to the existing ways of doing things. Storage arrays still exist and can take snapshots and do replication more efficiently than pushing everything through the Container Storage Interface and custom operators inside the Kubernetes cluser. Databases understand their internal data structures—and how to back up, replicate, and restore them—better than a bolt-on tool. Data still gets presented to applications via network connections and filesystems, though there are new abstraction layers in the middle such as Volumes or Stateful Sets.
Products like Kasten therefore need to both use the same techniques as in previous eras of infrastructure but also add a whole set of new ones that are compatible with the way container-based applications are written and operated. It's all much more complicated now.
I still think that a lot of application developers should slow down and stop shipping their laptop into production. Three-tier architectures are still useful, as I've written about at length. Putting stateful data into a structure that is designed to store state and keep it protected and available seems like a wiser choice than hacking an ephemeral container into not being quite as ephemeral any more.
But a lot of people disagree with this idea, so Kasten should enjoy plenty of growth as they discover that the data is the important part of their application and keeping it safe is probably a good idea.
I couldn't help myself with the headline alliteration/pun. It's a sickness.
See also
Related items

Containers Are The Future But The Future Isn’t Finished
Containers are the future, but there is still a lot of work to be done to make them good.
The Point Of Docker Is More Than Containers
The value of Docker is in what it enables, not the technology itself.

Droplet Computing Makes The Browser The Computer
Droplet Computing have used WebAssembly to turn your browser into a computer that can run any old application.